Figure R1. Scaling Diffusion Forcing Transformer and History Guidance. We showcase the video generation capabilities of our larger DFoT model, obtained by fine-tuning the Wan2.1 T2V-1.3B model, which was never trained to condition on images. With only 20k steps of finetuning under limited resources, the model is already able to generate image-conditioned videos (traditionally hard at this size) with varying history lengths. These results validate the scalability and effectiveness of our approach, including long video generation, flexible-length history conditioning, and improved quality and consistency in more dynamic, complex, and diverse scenes at a higher resolution of 832x480. Hover over the videos to see the text prompts, and tap the arrow buttons to view more videos.
Close-up view of a surfer riding a wave at sunset, with the camera smoothly following their dynamic movement across the water.
A cyclist pushes uphill on a winding road, with the camera keeping them centered, capturing their determination.
A static camera view of waves during sunset.
A monkey sits on a stone, looking around curiously, with the camera stationary, capturing the serene backdrop of the landscape.
A dog is preparing to sleep. It closes its eyes, then rests its head to the side on the ground, with the camera capturing its peaceful demeanor. The dog occasionally shifts its position, adjusting for comfort.
An aerial view of a tropical beach, with waves gently lapping the shore and palm trees.
(a) Diffusion Forcing Transformer's long video generation capability scales and generalizes well.
We present six 217-frame videos generated by Diffusion Forcing Transformer via 5x sliding window rollout, given an single random image sourced from the web (not in training data) and a text prompt.
Close-up view of a dog and a person's hands doing high five.
Close-up view of a person slicing a yellow bell pepper with a knife.
Car driving along the dessert highway.
A portrait of a woman turning her head to look directly at the camera.
(b) History Guidance improves the quality and consistency of the generated videos.
We compare the frame interpolation results given two frames (first and last) taken from random videos on the web and a text prompt, with (top) and without (bottom) History Guidance.
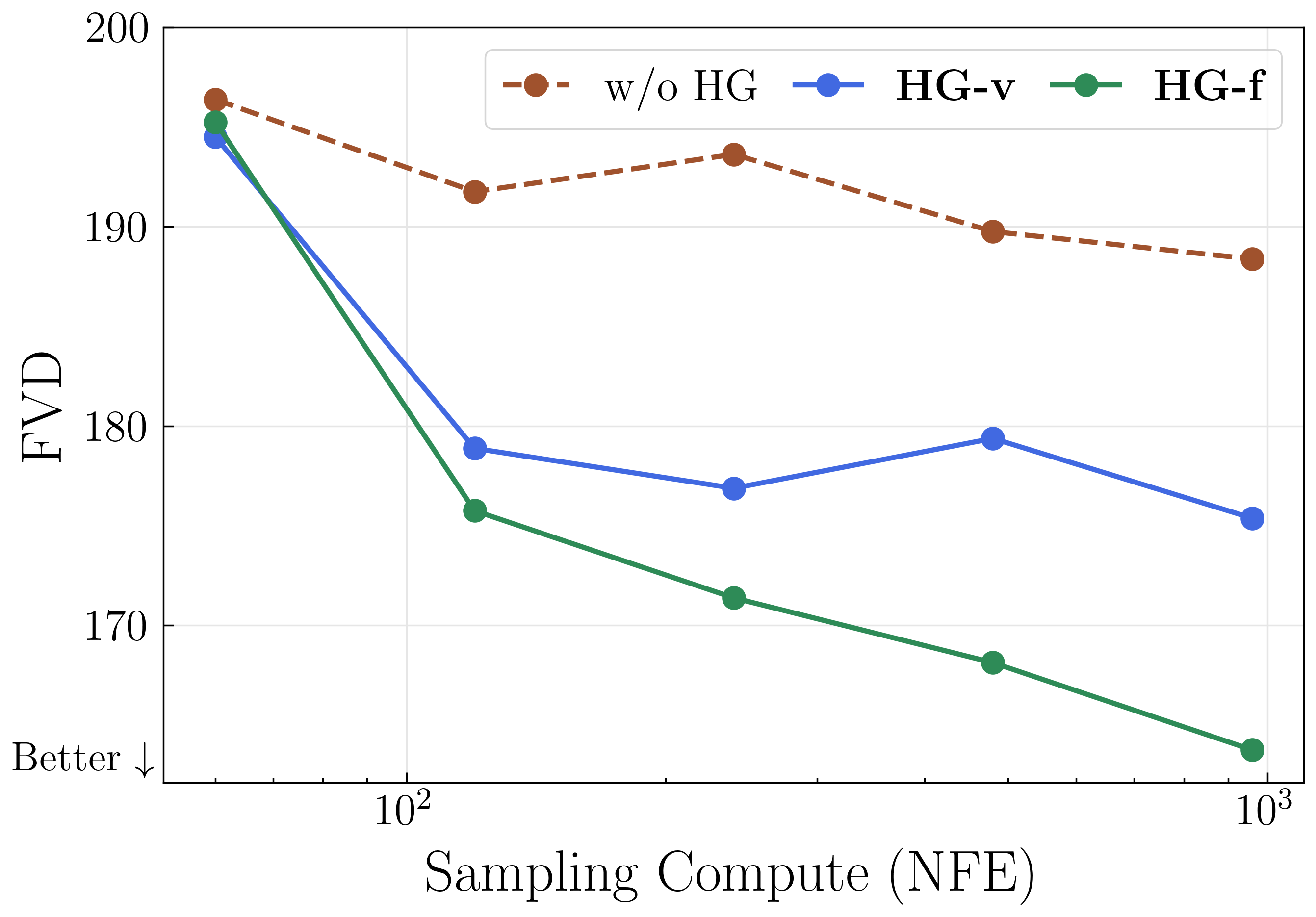
Figure R2. History Guidance efficiently utilizes the sampling compute budget. We compare the FVD of videos generated using history guidance variants (HG-v and HG-f) against those without HG, across varying sampling compute budgets. The budget is measured by the total number of function evaluations (NFE). Under the same sampling budget, HG-v and HG-f achieve significantly better (lower) FVD than w/o HG. This suggests that although history guidance requires multiple forward passes per timestep during sampling (HG-v = 2, HG-f = 3), it can be effectively compensated by reducing the number of sampling timesteps. The experiment setup is identical to Section 6.3.
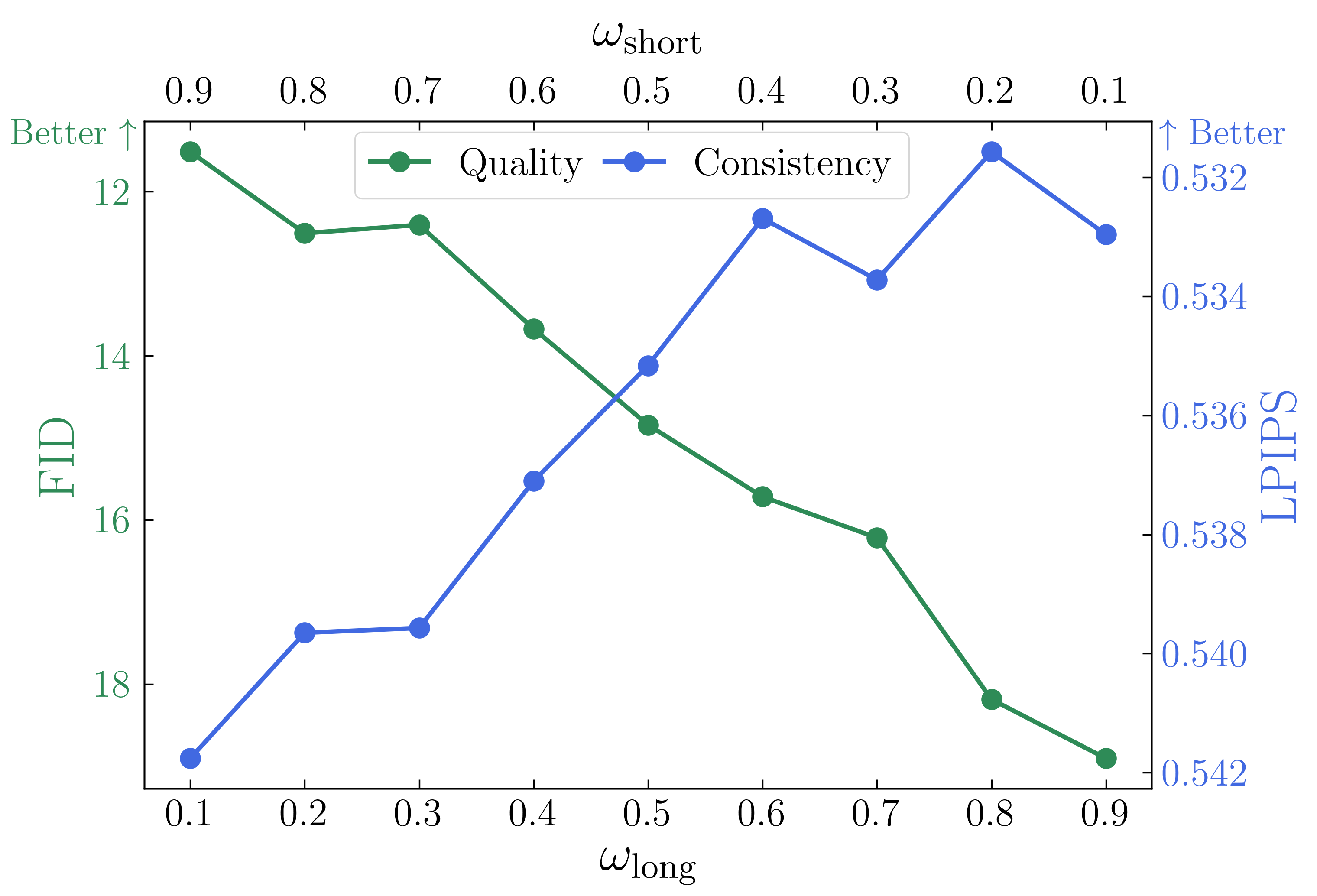
Figure R3. HG-t trades off long-term consistency and quality in long context generation. This figure illustrates the balance between long-term consistency, measured by LPIPS, and quality, measured by FID, of Minecraft videos generated using HG-t by varying the weights of combining short (ωshort) and full long (ωlong) history. Clearly, with increasing ωlong, the long-term memory improves, while the quality degrades. This clear negative correlation between the two factors suggests that HG-t can effectively trade off long-horizon memory and quality by mixing the two histories. The experiment setup is identical to Section 6.4 - Task 2.
Anonymous Submission
Five samples generated by Diffusion Forcing Transformer from a
single image. The model is trained only on the RealEstate10K
dataset but can roll out much longer than prior state-of-the-art
methods
[1][2].
We highlight samples with challenging motions (e.g. zooming out,
large rotation).
Ultra Long Video Generation
Diffusion Forcing Transformer (DFoT) along with
History Guidance Across Time and Frequency can stably
rollout extremeley long videos, such as the following 862-frame
video from a single test image from the RealEstate10K dataset.
Compositionality and Flexibility
DFoT learns the distribution of all sub-sequences than just
the full sequence, allowing conditioning on any length
history. Temporal History Guidance composes long
horizon behavior and local reactive behavior for new
capabilities.
Qualitative Comparisons
On standard benchmarks, the
Diffusion Forcing Transformer (DFoT) not only
matches or surpasses industry closed-source models trained with
large-scale compute but also enables long rollouts far beyond
the test lengths of these datasets. We can perform rollouts of
60 frames on the Kinetics-600 dataset, compared to the previous
benchmark of 11 frames, and at least 276 frames on the
RealEstate10K dataset, significantly exceeding the previous
limit of around 16 frames.
The figures below present qualitative samples generated by
different diffusion methods using the same architecture.
Standard Diffusion refers to the conditional
diffusion baseline trained for a specific test history length
(in contrast to DFoT's support for any history length).
Binary Dropout is an ablative baseline that
drops out frames during training to allow for flexible history
conditioning. Full-sequence Diffusion is the
traditional video diffusion method from
Ho et al. 2022,
which uses reconstruction guidance to enable flexible
conditioning.
Samples on Kinetics-600 dataset with a challenging setting of
predicting next 60 frames given 5 initial frames.
More samples on Kinetics-600 dataset with a challenging setting
of predicting next 60 frames given 5 initial frames.
Samples on RealEstate10K dataset conditioned on the first frame
and a camera pose sequence. This task is usually considered much
harder than interpolating between two frames, the traditional
video generation task on this dataset. In addition, we
deliberately choose challenging motions such as big rotations or
zooming out, and a big length of 276 frames.
More samples on RealEstate10K dataset conditioned on the first
frame and a camera pose sequence. This task is usually
considered much harder than interpolating between two frames,
the traditional video generation task on this dataset. In
addition, we deliberately choose challenging motions such as big
rotations or zooming out, and a big length of 276 frames.